
The Battle of the Pens: Insights into Detecting AI-Generated Text
Read SHL Labs’ latest insights from analyzing 1 million data points to detect human and AI-generated text.
Share
We are all intrigued by the capabilities that ChatGPT has to offer. With its ability to generate human-like text and answer just about any question, what does this mean for the future of assessments?
ChatGPT is a large language model released by OpenAI a few months ago. It is capable of answering questions across different domains, including follow-ups, and can even solve complex problems such as coding and logical reasoning. However, it also has significant limitations in terms of hallucinations and making up facts.
The virality of ChatGPT has sparked discussions about the future of tests and assessments in schools, universities, and workplaces. ChatGPT has demonstrated its ability to accurately solve many assessments, including the following examples:
- Would ChatGPT get a Wharton MBA?
- 17% of Stanford students admitted using ChatGPT in their assignments.
- ChatGPT banned by French University over plagiarism concern
- ChatGPT was banned by Indian, French, and US Colleges, Schools, and Universities to Keep Students from Gaining Unfair Advantage
Similarly, we have seen several scientific publications avenues blocking the use of ChatGPT in their manuscripts. For example, ChatGPT has also been accused of fake generations, which experts refer to as "hallucinations", when it provides a bogus citation-backed answer.
All the risks mentioned above are not only related to ChatGPT, but they are also true for other language models. There are many language models that are available to the public, and they are becoming more advanced every day.
Now the million-dollar question is:
Whether an AI-generated text detection algorithm can accurately distinguish between human-written and AI-generated text accurately, and where the current state-of-the-art techniques stand.
The last few weeks have seen many techniques that claim to accurately differentiate between human-written and AI-generated text. To answer the burning question, we present insights from one of the largest studies examining different techniques on more than 1 million essays written by humans and artificial intelligence together.
Dataset and algorithms
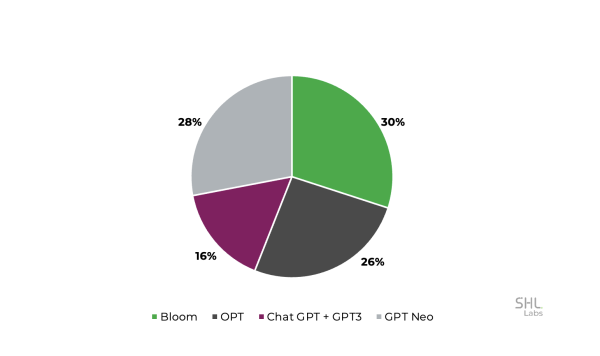
We acquired a dataset of 1 million human-written essays/ articles with an average length of 250 words. All these essays were written for 10 different prompts between January 2019 and October 2022. Further, we generated about 16,000 essays using large language models such as OPT, Bloom, GPT-Neo, GPT-3, and ChatGPT. The following pie chart provides a breakdown of the dataset.
We evaluated GLTR, OpenAI-GPT2 detector, Perplexity (PPL) features based (similar to GPTZero), and HC3-Roberta model (public release on January 18, 2023). We will discuss the implementation details of the compared AI-Text detection techniques in a future ArXiv study.
What are we measuring?
To keep it simple and understandable for a diverse population, we are going to work with two metrics.
- Error in detecting human-written essays (%): Fraction of essays that are human-written but the algorithm classifies them as AI-generated. Ideally, this should ideally be ZERO to minimize any penalty to the writer who is doing the work with honesty.
- Error in detecting AI-generated essays (%): Fraction of essays that are AI-generated but the algorithm classifies them as human-written.
What did we find?
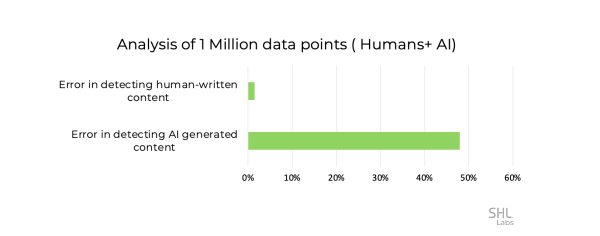
Insight #1: Human-written essays are likely to be misclassified as AI-generated on an average of nearly 1.5%. About 15,000 essays (from our 1M dataset) were detected as AI-written. This error is considerably high and could penalize valid submissions.
Insight #2: AI-written essays are likely to be misclassified as human-written nearly 48% of the time. This is huge as nearly half of the content goes undetected using current detectors.
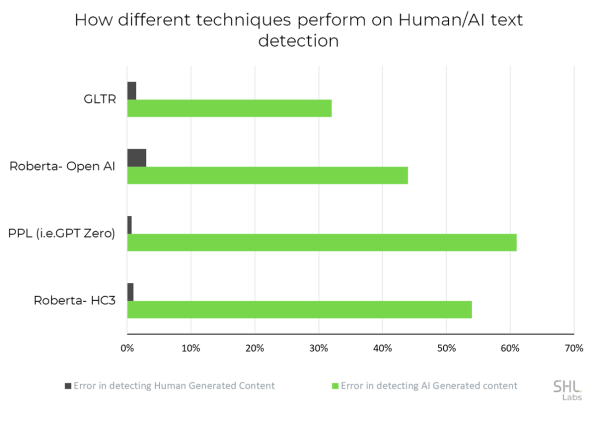
Insight #3: There is no consistent winner in detecting AI-generated and human-written text. Perplexity wins in detecting human-written text well but fairs poorly in detecting AI-generated text. GLTR provides the lowest error in detecting AI-generated text.
Insights #4: The efficacy of detection techniques can be influenced by the language model used to generate the text. Text generated by ChatGPT or GPT-3 is generally easier to detect compared to the text generated by lesser-known models such as OPT and Bloom, which may be less familiar outside of the AI community.
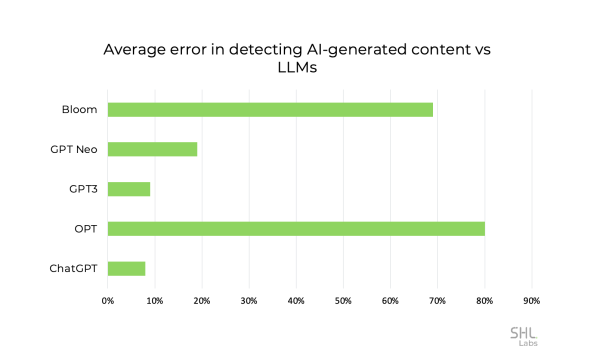
The final verdict is that current techniques are struggling to match the generative capabilities of large language models (LLMs), and sustained research efforts are needed. Our findings align with the recent announcement that detecting AI-generated text has an average error rate of 74%, compared to 9% for human-written text. OpenAI's larger corpus and varied content are expected to contribute to a higher error rate.
This blog post is the first in a series on this topic, and we plan to publish additional insights from our study in a scientific paper on ArXiv. Using our large corpus of human-written text to learn detectors will be one of our ongoing efforts. For example, what happens if humans and AI collaborated to write a piece of text or paraphrase using other tools such as Grammarly?
For more such interesting insights visit the SHL Labs page.









